|
Zhizhen Qin I am an Applied Scientist at NeuroSymbolic team in AWS. Prior to join AWS, I was a PhD student in Computer Science and Engineering Department at UC San Diego. My advisor is Professor Sicun Gao. My research interests include AI safety and machine learning. I have organized the AI for Math workshop at ICML 2025 and I am organizing the Math Reasoning and AI workshop at NeurIPS 2025. I serve as a reviewer for ICML2025, ICLR2025, NeurIPS2024, ICRA2024, and I am on the program committee for AAAI2026. |

|
News
|
Publications |
|
Estimating Control Barriers from Offline Data
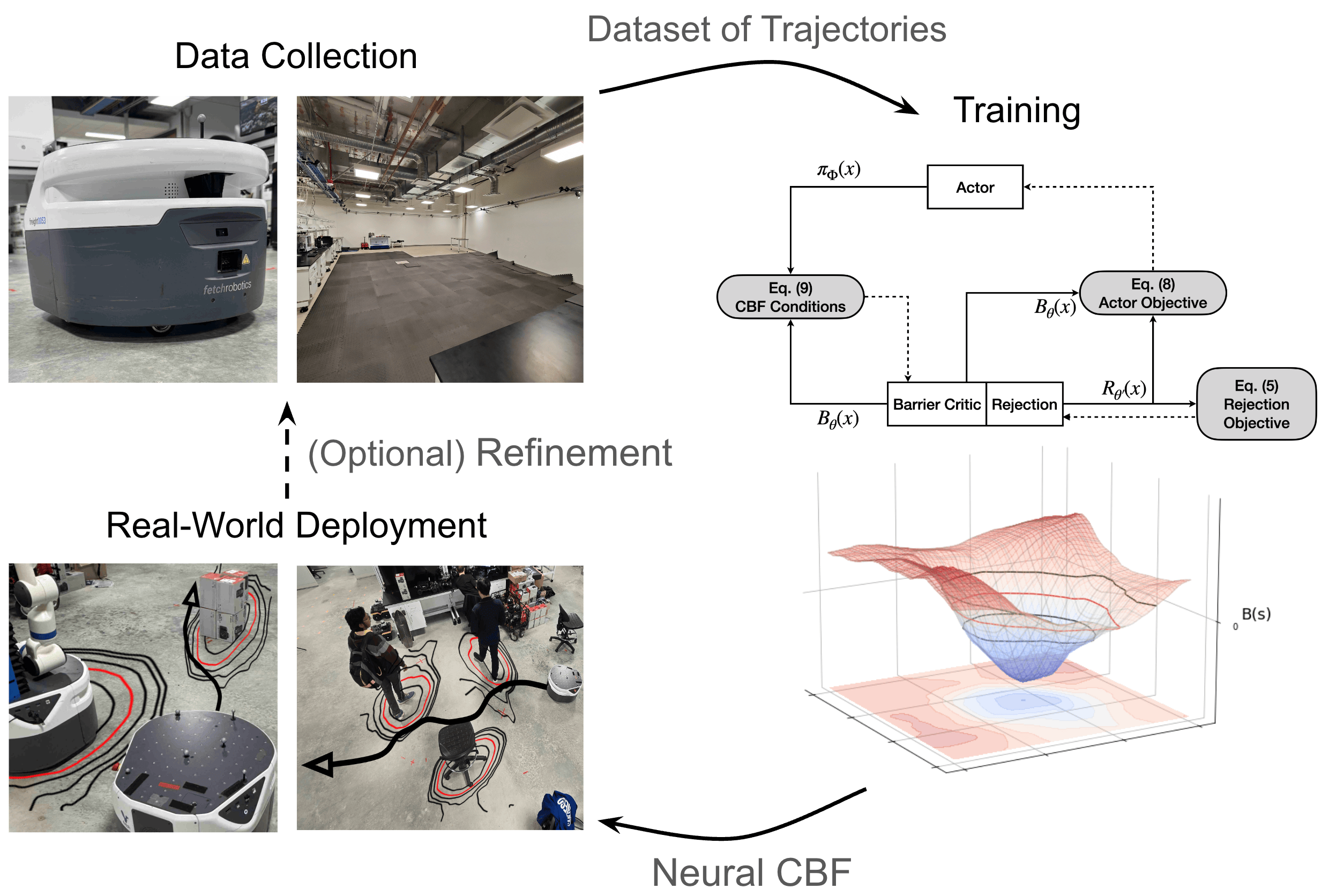
Hongzhan Yu, Seth Farrell, Ryo Yoshimitsu, Zhizhen Qin*, Henrik Christensen, Sicun Gao, ICRA, 2025 arXiv Learns neural control barrier functions from sparse offline datasets using out-of-distribution annotation techniques, enabling safe robot control without extensive online simulation or an expert controller. |
|
|
Patching Approximately Safe Value Functions Leveraging Local Hamilton-Jacobi Reachability Analysis
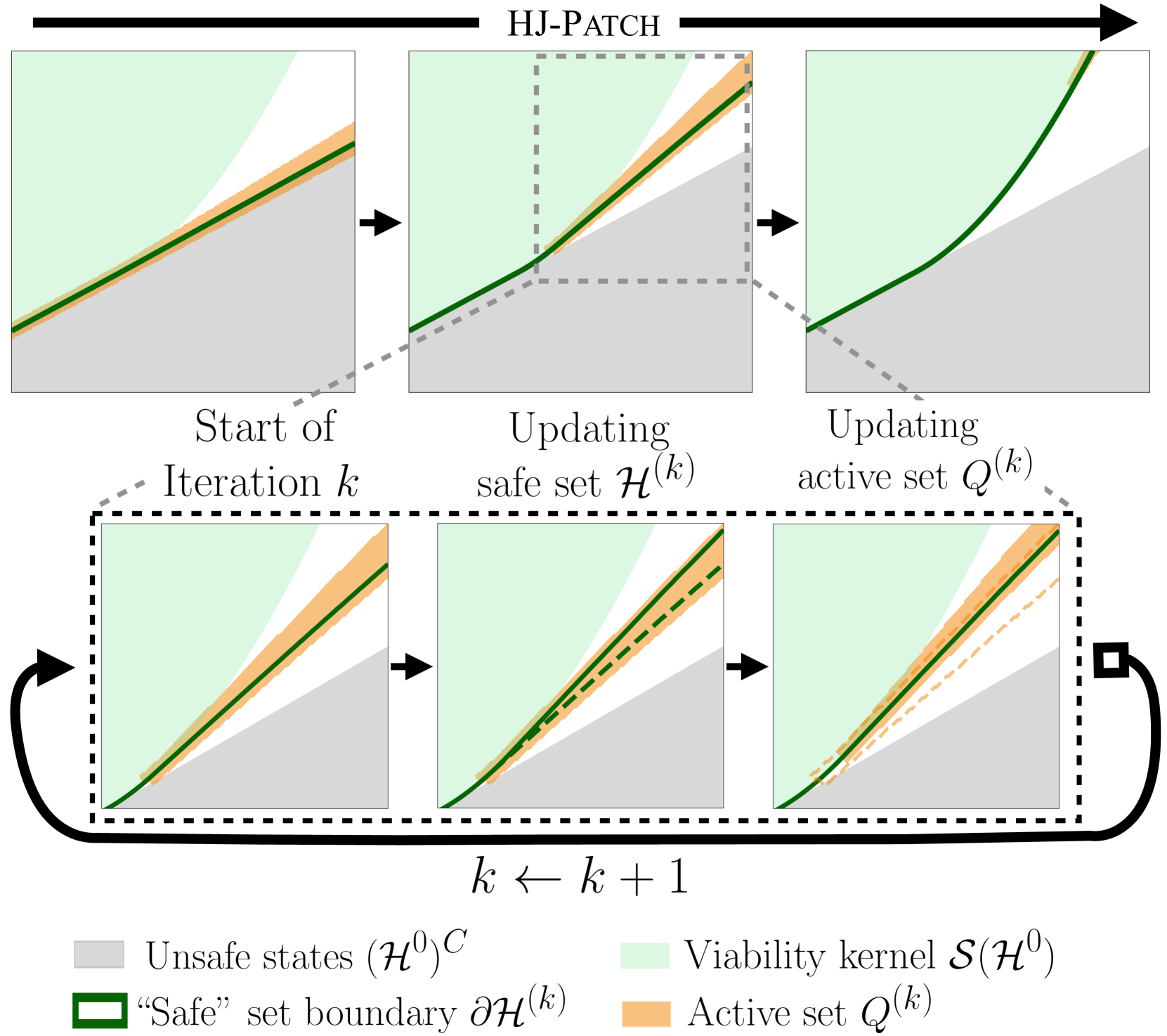
Sander Tonkens, Alex Toofanian, Zhizhen Qin*, Sicun Gao, Sylvia Herbert, CDC, 2024 arXiv Improves approximately safe value functions by patching unsafe regions using local Hamilton-Jacobi reachability analysis, enhancing safety guarantees for complex systems without retraining the full policy. |
|
|
SEEV: Synthesis with Efficient Exact Verification for ReLU Neural Barrier Functions
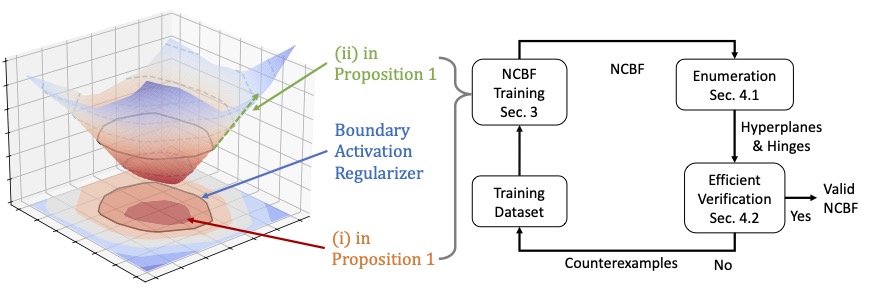
Hongchao Zhang*, Zhizhen Qin*, Sicun Gao, Andrew Clark, NeurIPS, 2024 arXiv | GitHub Jointly trains and verifies ReLU neural control barrier functions by regularizing activation patterns at the safety boundary to reduce verification cost, enabling counterexample-guided training for tighter safety certificates. |
|
|
Sample-and-Bound for Non-convex Optimization
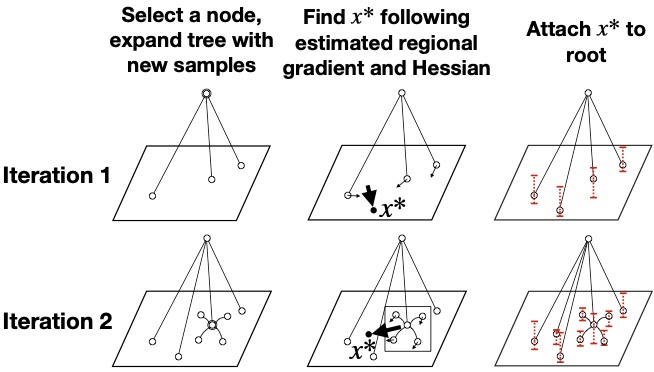
Yaoguang Zhai*, Zhizhen Qin*, Sicun Gao, AAAI, 2024 arXiv A Monte Carlo Tree Search framework for global non-convex optimization that uses interval bounds on function values and gradient information as uncertainty metrics, efficiently balancing exploration and exploitation. |
|
|
Policy Optimization with Advantage Regularization for Long-Term Fairness
in Decision Systems
Eric Yang Yu, Zhizhen Qin, Min Kyung Lee, Sicun Gao, NeurIPS, 2022 arXiv Enforces long-term fairness constraints in reinforcement learning by regularizing the advantage function during policy gradient updates, achieving better utility-fairness trade-offs without reward engineering or sacrificing training efficiency. |
|
|
Quantifying Safety of Learning-based Self-Driving Control Using
Almost-Barrier Functions
Zhizhen Qin, Tsui-Wei Weng, Sicun Gao, IROS, 2022 arXiv Learns neural almost-barrier functions to quantitatively certify the safety of deep neural path-tracking controllers, using neural network robustness analysis to identify certified and uncertified regions of the state space. |

Professional Service |
|
Workshop Organization
Program Committee / Reviewer
|

|
Website template from Jon Barron. |